















Больше информации ожидается в ближайшее время
Видеокарты GeForce RTX 3080 и RTX 3070 так впечатлили соотношением цены и производительности, что вряд ли кто-то расстроился из-за того, что Nvidia оставила за кадром многие технические характеристики.

Вероятно, узнаем мы о них уже после старта продаж, но кое-что всё же стало известно сегодня благодаря тому, что представители Nvidia ответили на некоторые вопросы пользователей Reddit.
Итак, благодаря этому мы теперь знаем, что новые видеокарты Ampere поддерживают HDMI 2.1 в его максимальной интерпретации, то есть с пропускной способностью 48 Гбит/с и со сжатием DSC. То есть видеокарты поддерживают разрешение 8K при 60 Гц и с активным HDR.
Технология RTX IO не будет иметь каких-то особых требований к твердотельным накопителям. Это должны быть SSD с поддержкой NVMe и с интерфейсом PCIe 4.0. И чем быстрее будет накопитель, тем эффективнее будет работать RTX IO.
Кроме того, Nvidia немного рассказала о конфигурации её новых GPU. Напомним, новые видеокарты удивили огромным количеством ядер CUDA — их оказалось вдвое больше, чем утверждали все источники. К слову, оказалось, что производители видеокарт до самого анонса не знали об этой особенности, что и объясняет дезинформацию.

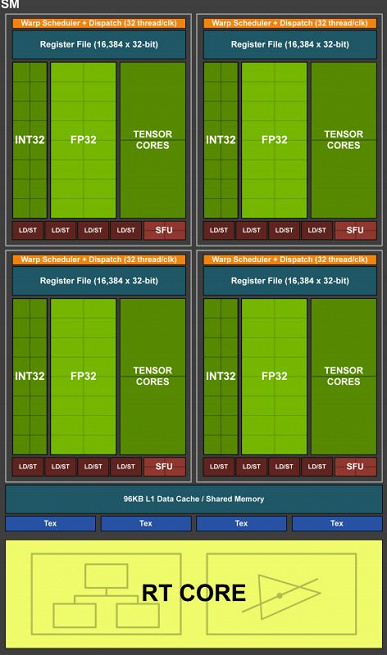
Как можно видеть, каждый вычислительный блок в составе кластера SM содержит одну структуру с ядрами FP32 (это и есть ядра CUDA) и одну структуру с таким же количеством ядер FP32 и таким же количеством ядер INT32. То есть ядер CUDA попросту стало вдвое больше в рамках одного блока, чем было в Turing. Однако это не привело к двукратному росту производительности в играх, потому что реализация Ampere подразумевает, что за один такт каждый блок способен выполнять либо 32 операции ядрами FP32, либо 16 операций ядрами FP32 и 16 операций ядрами INT32 — всё вместе одновременно задействовано быть не может. Но при этом, если говорить исключительно о ядрах CUDA (FP32), они могут быть задействованы сразу все, а в каждом кластере SM их теперь 128 против 64 у Turing.
А ещё у Ampere выросла пропускная способность кэш-памяти первого уровня: до 219 ГБ/с против 116 ГБ/с у Turing (на примере RTX 3080 и RTX 2080 Super).


